Direcionando Decisões de Negócios Usando Data Science e Aprendizado de Máquina
No LinkedIn, temos mais de 630 milhões de membros, 30 milhões de empresas e 90 mil escolas em nossa plataforma. Como a maior rede profissional, o LinkedIn transforma empresas mudando a maneira de contratar, comercializar, vender e trabalhar. Os membros usam o LinkedIn para se conectar com outros profissionais, expandir suas redes, procurar novas oportunidades de emprego e acompanhar as novas tendências. Essa rede cria e nutre um ecossistema em que membros, empresas, escolas, empregos, habilidades e conhecimento têm muitos relacionamentos interconectados. Para ajudar a estabelecer e analisar tal ecossistema em escala, recorremos ao aprendizado de máquina.
Em um tutorial da recente Strata Data Conference, em São Francisco, compartilhamos nossas experiências e sucesso ao alavancar técnicas emergentes para impulsionar decisões inteligentes que levam a resultados de impacto no LinkedIn.
Começamos o nosso tutorial, abordando duas questões importantes:
- Como você determina a métrica certa (KPI) para uma meta de negócios?
- Como você testa um novo recurso no site para tomar decisões de negócios?
Compartilhamos alguns problemas reais de negócios e exemplos de projetos para demonstrar como nossos cientistas de dados lidam com esses problemas no LinkedIn.
Correspondência de KPIs e metas de negóciosPara projetar um KPI de negócios, há muitos elementos a serem considerados. Um KPI deve estar alinhado com os objetivos finais do negócio, e não com números de curto prazo. Precisa ser simples e interpretável; precisa ser acionável e móvel. Isso muitas vezes deixa os cientistas de dados com a importante responsabilidade de traduzir uma questão de negócio difusa em uma questão de ciência de dados que usará uma análise rigorosa para obter resultados e, posteriormente, ser traduzida de volta para os termos de negócios. Com esses princípios em mente, muitas vezes somos encarregados dos seguintes tipos de perguntas: “O que é um membro ativo?” “Como definimos um cliente altamente engajado?” E assim por diante. Quando esse KPI for determinado, em seguida, nos concentraremos em melhorar a direção.
Testando recursos e tomar decisões de negóciospara testar um novo recurso, o que fazemos extensas experimentos controlados, também conhecido como o teste A / B . O LinkedIn tem sua própria plataforma de testes A / B que permite configuração conveniente e rápida iteração de experimentos. A qualquer momento, a plataforma executa centenas de experimentos.
O processo de ciência de dados e aprendizado de máquina
Durante nosso tutorial, falamos sobre o processo de aprendizado de máquina para um modelo a ser implantado em produção no LinkedIn. Este processo tem seis etapas principais:
- Formação de problemas
- Preparação de rótulo
- Engenharia de recursos
- Aprendizagem de modelos
- Implantação de modelo
- Gestão de modelos
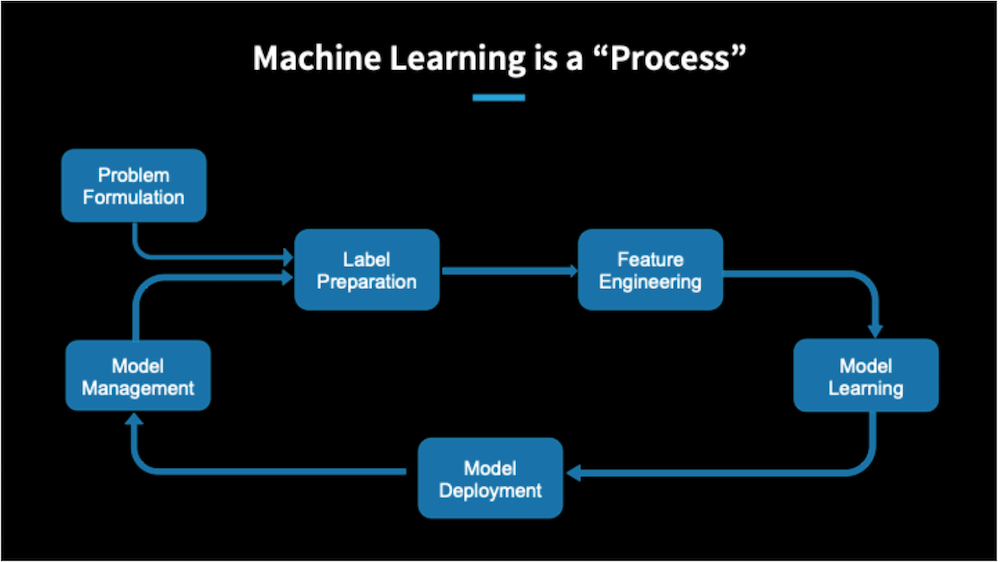
Formulaçãodo problema A definição do problema é fundamental para o sucesso de qualquer projeto. A pré-análise é frequentemente realizada para entender os problemas e desafios atuais do negócio, juntamente com o que queremos alcançar e como alinhar isso com as prioridades do negócio.
Preparação de rótulos Osdados rotulados são o que estamos prevendo em um cenário de aprendizado de máquina (por exemplo, um conteúdo relevante em um sistema de recomendação de feed). As definições de etiqueta são fundamentais para treinar, testar e validar conjuntos de dados. Dependendo das implicações e prioridades do negócio, a definição do rótulo pode ser diferente. Como exemplo, para desenvolver um problema de previsão de rotatividade, os rótulos podem ser definidos como completamente rotativos (taxa de renovação = 0) versus não totalmente rotatividade (taxa de renovação> 0). Alternativamente, a taxa de desligamento pode ser definida como a rotatividade parcial (taxa de renovação <1) versus não rotatividade (taxa de renovação> = 1). A primeira definição se encaixa melhor quando nos concentramos em manter os clientes, enquanto a segunda definição se encaixa melhor quando estamos focados no crescimento.
Recursos de engenharia derecursos são as entradas para um sistema de aprendizado de máquina; para um sistema de recomendação de feed, o recurso é o conteúdo. Muitas vezes nos deparamos com muitos recursos de várias fontes de dados. Assim, devemos primeiro coletar os recursos que não são apenas significativos para resolver nosso problema, mas também de acordo com os rótulos que definimos. Em seguida, integramos esses recursos ao rótulo, tomando cuidado com o alinhamento para recursos dinâmicos. Mais tarde, podemos limpar e realizar a transformação para revelar melhor os padrões dos dados.
Aprendizagem de modelosComeçamos particionando nossos dados em conjuntos de treinamento, validação e teste. Então, treinamos nosso modelo com o conjunto de treinamento. Ao fazer isso, devemos escolher nosso solucionador considerando o tipo de problema, os requisitos do sistema e também o equilíbrio entre desempenho e interpretação. Para escolher um solucionador com os parâmetros mais bem executados, também podemos executar uma pesquisa de hiperparâmetro. Em seguida, usamos diferentes técnicas de avaliação para escolher o melhor modelo usando o conjunto de validação. Ao escolher o melhor modelo, devemos também considerar as métricas de negócios. Em seguida, apresentamos os resultados do nosso modelo no conjunto de testes.
Implantação do modeloDepois que o processo de modelagem terminar, implementamos e executamos o modelo em produção. Isso nos permite programar e executar o pipeline de pontuação regularmente.
Gerenciamento de modelosDepois de implantar o modelo, executamos regularmente o monitoramento de desempenho de recursos e modelos para ver como o modelo está funcionando e se está utilizando o conteúdo correto dos dados. Se decidirmos atualizar nosso modelo, reciclaremos o modelo e, em seguida, conduziremos o teste A / B para comparar o novo modelo com o modelo antigo. Dependendo dos resultados do teste A / B, decidimos qual modelo usar na produção.
Solução de problemas
Mesmo que passemos pelas seis etapas do processo de aprendizado de máquina, há uma chance de que nosso modelo não atinja o desempenho desejado. Isso acontece porque há muitas armadilhas e desafios comuns que podem surgir durante o processo. Durante nosso tutorial, falamos sobre os dois desafios mais comuns: interpretação de modelos e qualidade de dados.
Interpretação do modeloA interpretação do modelo é um dos desafios que enfrentamos em nosso trabalho do dia-a-dia. Quando apresentamos nossos resultados de modelagem para nossos parceiros de negócios, eles se preocupam não apenas com os resultados, mas também com o "por quê?". Podemos usar a importância do recurso (proveniente do modelo de aprendizado de máquina usado para gerar os resultados) para explicar os principais impulsionadores dos resultados, mas esse método pode apresentar algumas desvantagens, como a dificuldade em interpretar o ranking de variáveis correlacionadas ou o viés para variáveis com mais categorias. Por exemplo, digamos que estamos construindo um modelo para prever quem devemos enviar e-mail para a assinatura de carreira usando a regressão logística. Suponha que tanto a pesquisa de emprego de recurso quanto a visualização de trabalho de recurso são importantes para decidir a quem devemos enviar o email. Se esses dois recursos também estiverem correlacionados,
Em vez disso, usamos interpretação de recurso em grupo. Nesse método, agrupamos os recursos em blocos com significado semântico e, em seguida, criamos modelos com base apenas no subconjunto dos recursos de cada bloco.
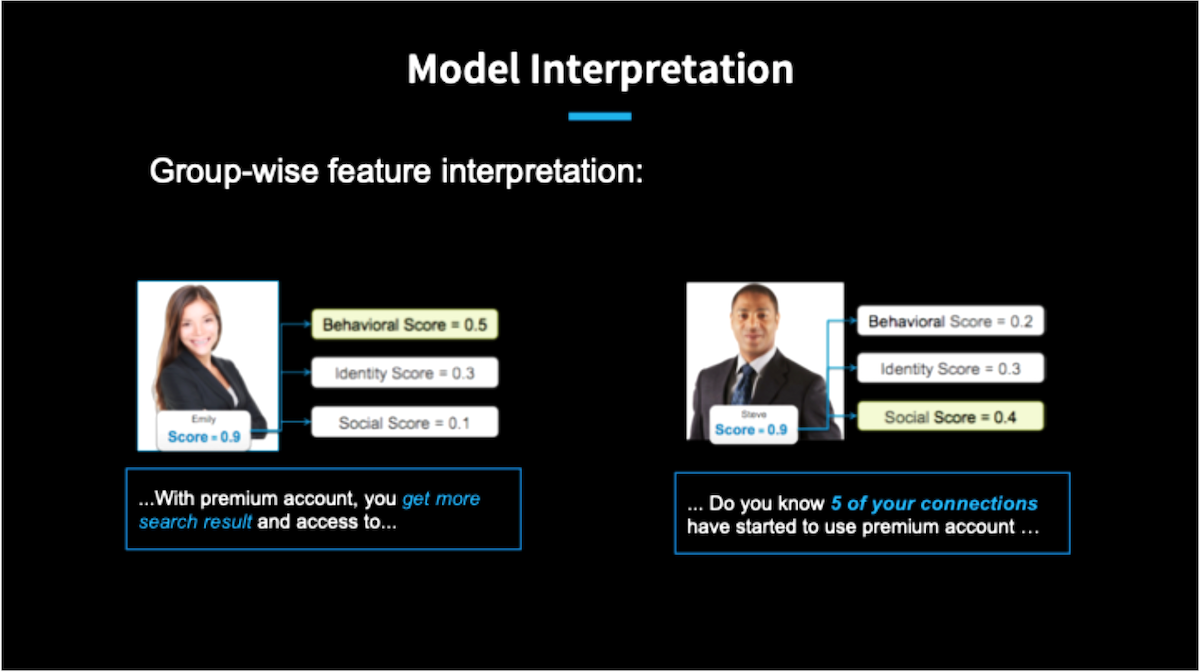
No exemplo acima, tanto Emily quanto Steve receberam altas pontuações de 0,9 do modelo mestre, que usa todos os recursos. No entanto, isso apresenta uma discrepância de suas pontuações dos outros três modelos (Behavioral, Identity, Social) que são gerados por recursos relacionados a comportamentos, identidade e características sociais, respectivamente. Os resultados acima sugerem que Emily tem uma pontuação alta com o modelo mestre por causa de suas características comportamentais, enquanto Steve recebeu uma pontuação alta por causa de seus recursos sociais.
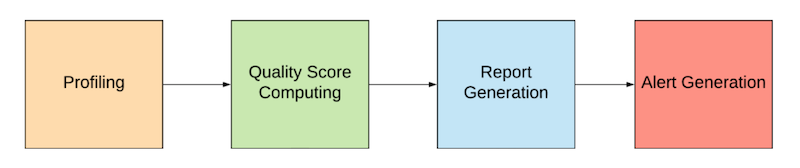
Qualidade de dadosUm exemplo de dados de baixa qualidade é a falta de dados históricos ou dados ruidosos. Para descobrir possíveis problemas com antecedência, temos um fluxo de monitoramento de qualidade que gera insights para a qualidade dos dados para cada semana, mês ou ano. Com esse fluxo, geramos regularmente perfis de recursos e usamos estatísticas de perfis de recursos para calcular um índice de qualidade. Com esse índice de qualidade, calculamos a pontuação de anomalia do índice de integridade, verificando a porcentagem de recursos de anomalia. Armazenamos essas informações em uma tabela de controle de qualidade para refletir o status para ver se um determinado recurso pode ser usado para modelagem ou não. Se virmos algum problema, enviamos um alerta para o proprietário do recurso.
Estudo de caso: marketing
Graças ao rápido crescimento dos recursos de dados, é comum que os líderes de negócios apreciem os desafios e a importância de extrair informações dos dados. Em nosso tutorial, apresentamos um estudo de caso sobre marketing, um campo que tem sido considerado tradicionalmente mais artístico do que quantitativo, até os últimos anos, com o surgimento do big data. Muitos dos dados envolvidos descrevem os clientes, tais como quem são, o que fazem e, mais importante, suas interações dentro de suas empresas. A mineração dessas informações torna-se uma parte importante da prática de marketing para melhor entender seus clientes.
Neste exemplo, demonstramos como as técnicas e metodologias da ciência de dados podem ajudar as decisões de marketing das empresas por meio da aquisição de clientes, envolvimento do cliente e prevenção da perda de clientes. A combinação de ferramentas e técnicas de ciência de dados com experiência de marketing e perspicácia de negócios leva ao sucesso do marketing orientado por dados.
Na aquisição de clientes, marketing e vendas gostariam de identificar os clientes certos para direcionar seus esforços e avaliar os investimentos de marketing em diferentes canais e ajudar a determinar futuras alocações de recursos. Ferramentas de ciência de dados como modelagem de mix de mídia, modelo de resposta do cliente e abordagens de atribuição multitoque podem ser aplicadas para solucionar esses problemas.
Na retenção e engajamento do cliente, as ferramentas de ciência de dados poderiam ajudar não apenas na mensuração dos níveis de engajamento de cada cliente ou segmento, mas também no modelo de resposta dinâmica do cliente para avaliar a eficácia de várias intervenções de marketing para incentivar o engajamento do cliente e ajudar a projetar mensagens direcionadas aos clientes certos para melhorar a retenção. Além disso, através da análise das ações e engajamento do cliente, um modelo de valor vitalício do cliente (CLV) poderia ajudar a identificar os clientes mais valiosos, em termos de receita ou lucro que o cliente traria, através de suas próprias compras em um ou vários produtos e categorias, e através de sua influência para outros clientes.
Por fim, as abordagens de modelagem estatística e comportamental poderiam ajudar a prever os clientes com maior probabilidade de rotatividade, com base nas informações observadas relacionadas ao cliente e suas interações com o marketing e o produto da empresa. Depois que esses clientes são identificados, a equipe de marketing cria a mensagem certa para reconquistar o cliente e evitar que um cliente valioso seja revolvido.

Membros da equipe de ciência de dados do LinkedIn na Strata Data Conference.
Nota do Editor: Para saber mais sobre ciência de dados de ponta a ponta no LinkedIn, ouça o mais recente podcast This Week In Machine Learning e AI , com o cientista sênior de dados Burcu Baran .
---------------

Cursos para horas complementares
Cronograma OAB - CLIQUE AQUI
Curso Online de Revit
Curso Online de BIM
Como Vender Moda pela Internet
